Restoring Compressed Media
A Fast, Perceptual NoGAN Approach
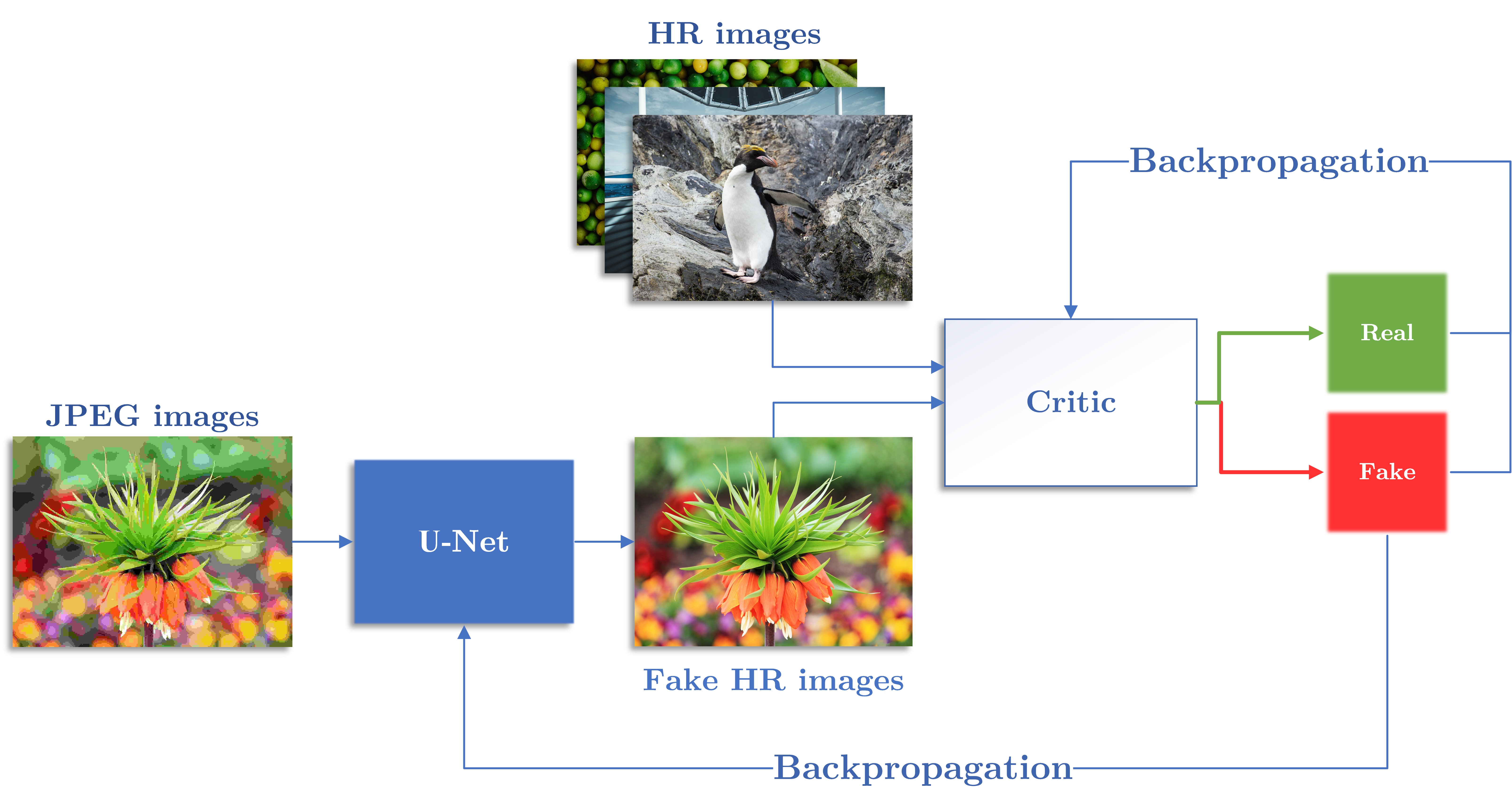
Lossy compression is the backbone of modern media streaming and storage, but it comes at a visual cost. As compression rates rise to accommodate bandwidth limitations, algorithms like JPEG introduce distinct visual distortions. A new study addresses this challenge by adapting the “NoGAN” training strategy, combining it with efficient architecture to perform Visual Quality Enhancement (VQE) and super-resolution suitable for real-time applications.
The Artifact Problem
To understand the solution, one must first identify the specific artifacts introduced by lossy compression. Algorithms typically discard high-frequency data and approximate color gradients to save space. This results in:
- Blockiness: Visible borders between the pixel blocks (e.g., 8x8 or 16x16) used by the encoder.
- Ringing and Mosquito Noise: Visual ripples near sharp transitions, such as text, caused by the loss of high-frequency information.
- Contouring: The appearance of sharp bands in smooth gradients (like skies or walls) due to color quantization.
The goal of VQE is to act as a post-processing step that restores these lost details and removes artifacts immediately before presentation.
The NoGAN Training Strategy
Generative Adversarial Networks (GANs) are capable of reconstructing “natural” textures, but they are notoriously unstable to train. To solve this, the study employs NoGAN, a training methodology popularized by the DeOldify colorization system.

The core concept of NoGAN is to minimize the duration of the direct adversarial conflict between the generator and the discriminator. The process involves three steps:
- Generator Pre-training: The generator is trained in isolation using a perceptual loss function to learn structure and content.
- Discriminator Pre-training: The discriminator is trained separately to distinguish between original high-quality images and the “fake” restored versions.
- Short Adversarial Handoff: Finally, the standard GAN “game”—where the networks compete—is run for a very short period to fine-tune the realism of the output.
In the experiments conducted, the separate pre-training lasted for 20 hours, while the final adversarial step required only one hour.
Architectural Optimizations for Speed
While NoGAN provides stability, the researchers introduced significant architectural changes to ensure the model was fast enough for video processing. The original DeOldify architecture relied on a heavy ResNet101 backbone.
This study replaces that heavy backbone with MobileNetV3, which uses only 5.5 million parameters. This switch drastically reduced the computational load. On an NVIDIA Titan X, inference time dropped from 0.27 seconds to 0.12 seconds per frame when using the “Small” MobileNet variant. This speed is critical for processing large video archives or enabling client-side enhancement.
Perceptual Loss and Patch-Based Training
The most significant deviation from traditional restoration methods lies in how the model learns to “see” artifacts.
First, the study utilizes a Patch-Based Training approach. Since compression algorithms operate on small blocks of pixels, artifacts are local phenomena. The model is initially trained on 64x64 pixel patches rather than full images. This focus allows the network to effectively target high-frequency noise like ringing and aliasing, which are often overlooked when a discriminator assesses a whole image at once.
Second, the generator is pre-trained using the Learned Perceptual Image Patch Similarity (LPIPS) metric. Unlike Mean Squared Error (MSE) or VGG feature loss, LPIPS is designed to mimic human visual perception.



The Perception-Distortion Trade-off
The results of this study highlight the known “rate-distortion-perception” trade-off: optimizing for statistical similarity often hurts perceptual quality.
In objective testing, models optimized for Structural Similarity (SSIM) achieved higher statistical scores but produced images that looked less natural to human eyes. Conversely, the LPIPS-based model produced superior perceptual results. In a subjective study with 55 participants, the LPIPS-based network achieved a Mean Opinion Score (MOS) of 4.03 (on a 5-point scale), significantly outperforming the SSIM-optimized network, which scored 3.28.
Conclusion
By leveraging the stability of NoGAN training and the efficiency of MobileNetV3, this approach offers a practical solution for revamping low-quality multimedia. The shift toward perceptual loss functions (LPIPS) and patch-based training proves that tackling compression artifacts requires mimicking how humans perceive details, rather than just minimizing pixel-level errors (like MSE). The resulting system is not only capable of restoring static images but is also fast and stable enough to enhance video streams, effectively removing noise and revitalizing old content for modern displays.
The code is available on GitHub
